In my enthusiasm for fixing fonts for JSesh 7.9, I made a choice which is perhaps a bit too hasty, palaeographically speaking.
The E1 sign is a bit problematic in Gardiner fonts. There should probably be two different signs; one is the bull, kꜣ; the other is cattle (mnmn.t, ꞽḥw). In hieroglyphs, they tend to have different shapes, in particular regarding their horns. Hieratic texts tend to erase the difference, save the Abusir Papyrus, but then the shape is more a cursive hieroglyph than actual hieratic.
Gardiner states: the sign is apt to vary in form according to the sex and species demanded in the particular case.
Now, we really need two versions of the sign. One with short horns, and the other with lyre-shaped horns. I will, in the following week, propose a version of JSesh (7.9.2) with both.
- E1
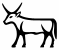 : I will revert to this shape for E1, as it is closer to the shape in Gardiner fonts;
: I will revert to this shape for E1, as it is closer to the shape in Gardiner fonts; - E1F
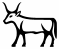 : the bovid with lyre-shaped horns, to be used if one wishes to make the distinction.
: the bovid with lyre-shaped horns, to be used if one wishes to make the distinction.
Note that this tends to comfort me in my idea that, in hieroglyphic text encoding, we need a way to explicitly encode how precise we want to be.
If we specifically consider text databases. With the current system, if you use E1F to encode a bovid in an offering list, and you have previously encoded other texts, you will get:
- texts where E1 is used for sign which can have either short or lyre-shaped horns;
- texts where E1F is explicitly used for lyre-shaped horns.
As far as the linguistic content of the text is concerned, it won't really be an issue. But in a grammatological perspective, especially if you want to compute some kind of statistics, your encoding would be of little use.
We probably should have three codes here:
- a code which corresponds more or less to Gardiner E1 : ambiguous sign for bovid, seen linguistically;
- an explicit code: E1 with short horns;
- another explicit code E1 with lyre-horns.
I already wrote about this subject. Consider, in particular, the practice of Sethe for the Pyramid Texts. Asking colleagues to make an explicit choice each time they type a text is probably too cumbersome. Instead, the solution I consider is that there would be a default mode one could choose (linguistically oriented or palaeographically oriented), and the possibility to switch from one to the other for single signs (or sign sequences? but it would not be error-proof).
The linguistic mode would be the default when encoding text in Hieratic.
This would solve part of the problem, as it would be clear, when a sign is encoded in linguistic mode, that the encoding states nothing about its actual shape.
A specific (optional) visualisation mode, using for instance a color code, would allow one to visualise how each sign is encoded.
Note that this doesn't fully solve the problem, as the definition of what is a sign is not always clear. For E1, I guess that what we really have is more two logically different signs, with a fuzzy boundary between them.