In this article, I will try to explain what I think ideal encoding of hieroglyphic text should be. I will then proceed to explain what it would mean in practice.
I will probably write multiple versions of this page, after discussion with users.
The purposes of encoding
JSesh can be used in many different ways, but basically, I can distinguish :
- people using JSesh with the printed, published result in mind;
- people using JSesh to create databases:
- for short quotation, typically word-level (proper nouns, titles, toponyms)
- for full-text searching
- large-grained: focus on lexicography and grammar, not so much on actual sign shapes
- fine-grained: trying to get near-epigraphic precision (often seen in the publication of Ptolemaic texts)
In the first case, JSesh is mostly seen as a drawing program for hieroglyphs. The actual encoding doesn't seem very important. Custom signs can be added quite freely if the user wishes so. The user might face two problems:
- if the JSesh files are kept (which should always be the case!!!) and the shape of a sign changes in the JSesh library, there might be unwanted differences between texts made with a version A of JSesh and texts made with a version B of JSesh.
- encoding a text takes a lot of time; so, even if printing it was the first idea, it would be a pity not to use the text to make searches.
Encoding for databases is different. Basically, you want:
- to be able to search your database;
- to be able to create statistics on it.
In this case, sign variants become a huge problem. For searches, JSesh includes some data about sign variation. It is currently not precise enough, but, in theory, it might be used to perform a full database search for a sign and all its variants, so that a search for i-m will also retrieve occurrences of i-G17A. However, this requires some programming, which is handled by JSesh, but probably not by your favourite database engine.
Things are way worse for statistics. If you bother to encode variants, it means you are interested by them (that they are meaningful to you). For statistics to be interesting, the text need to be encoded with some degree of consistency. For instance, if you bother to encode T22A instead of T22, it must be because the original text actually contains T22A. The same goes for encoding V23A instead of V23. My position on the subject is basically that if you feel unsure about what to do, use the most standard code possible; i.e. the code in the original Gardiner list.
If you gather texts from various encoders, don't expect too much consistency in the variant selection. Even expert will probably have different views on what is relevant and what is not. You may try to set a guideline for a particular database, but it definitely requires a lot of work. One of the reasons for this, apart from the different views scholars may have about what is relevant or not - and in what context, is that the level of detail provided by the current sign collection is not consistent. Very secondary variants may be encoded for some signs, simply because of the history of the manuel de codage, while important variation may be unavailable.
Traditions play a role too. I guess that colleagues encoding the following extract of the early Middle Kingdom Stela Louvre C252:

will not hesitate to render the 'mj' sign as W19, even though the original text is noticeably different. The same will go for the "wood" sign, and the encoding wa:a:n-m:xt-x*t:HAt-W19-t:Z2:f (T21:D36:N35-G17:M3-Aa1*X1:F4-W19-X1:Z2:I9) is quite likely to be used here.
(as an aside, I have actually written wa:a:n-m:xt-x*t:HAt-W19-t:Z2:f, but there is a one-to-one mapping between this encoding and T21:D36:N35-G17:M3-Aa1*X1:F4-W19-X1:Z2:I9, which means the normalization here is not an issue).
On the other hand, a colleague typing the following text from Edfu :

is rather likely to complain that the closest sign available in JSesh, N37A, N37A has only two strokes.
Variants, their encoding and issues
It's quite obvious that some variants are intentional and have a meaning. For instance, wr:r-A19 and wr:r-A109F are both spellings of wr, chief. But the second determinative clearly adds a specific nuance to the word: (Libyan) chief.
In other cases, the meaning is not obvious. For instance, Stela Cairo CGC 34 504 uses many different spellings for First person pronoun : A42A, A43B... The question whether it's linked with the context, and hints to diffent aspects of kingship, or whether the goal is more graphical variety is a priori open. A systematic use of span A42 in all cases will properly encode the text, linguisticaly speaking ; but we will certainly lose an interesting variation in the text itself.
Regarding N37A vs N37 vs , The difference between N37A and N37 is here mainly diachronic but to make things more complex, N37A is in fact a variant of N38, which, before the XIth dynasty, had a different meaning from N371.
So, the encoding choices would be to:
- use N37 instead of N37A. It would ease searching, without losing much linguistic information, as it's a systematic modification ;
- use N37A ; the actual sign is a variant of N37A. The actual interest would be mostly statistical. If one wants to trace the development of sign variants, for instance. A problem for this approach is that it requires the same level of precisions in the whole database.
- add a new code for
. Here, the question might be to decide if the difference between N37A and
This being said, as a personnal opinion, I find that we are usually too cautious when encoding. No two signs are exactly the same. Unless your problematic is specifically about classifying a specific sign variant, you should probably trust yourself and read the text instead of trying to use fonts to make a facsimile.
We might also look at what colleagues in other domains are doing. Medievists who are interested in initial letters in manuscript would encode the text, and add information to the initials with additional information, usually using XML.
Signs, classes and tokens
During my studies in computer science, I attended to a conference by Jacques Arsac, one of the fathers of computing in France. He told us about nominalism and medieval philosophy, for a good reasons: the problems of building computer models are quite similar to those met by 12th century scholars.
When we create a database for digital humanities, or when we encode a hieroglyphic text, we might think we are modeling the actual archeological artifact. In fact, what we are modeling is our view of this artifact.
Once this is understood, the idea is that we might try to represent our data as layers, from the most factual to the most interpretative. Regarding hieroglyphs, the most factual level would be the original document, or its direct representation (maybe a fac-simile), and the most interpretative, if we stop at text representation, would be the identification of the various signs - in their linguistic value. However, an explicit representation of those various level would probably be a deterrent for would-be users. But a middle ground can be found.
Back in 2013, S. Polis and the present author attended a conference in Tours, and we presented a paper about hieroglyph representation and the shortcomings of the Manuel de Codage2. We advocated the distinction between a sign, as a linguistic marker, its variants, and the corresponding graphical shapes. Our view were converging with those of Dimitry Meeks3. Stephane Polis then started the Thot Sign List to provide a database of signs as a basis for encoding.
The view I'm about to present is my own interpretation of what can be done, based on the ideas and vocabulary behind the Thot sign list.
-
the most material thing we can represent is in fact a picture, called a token in the Thot sign list. It can be a
particular sign in situ, a photography, a fac-simile, a character in a font, or a hand-drawn character in a book. In practice, in a word processor, the token will always be a specific drawing, from a font or from a file, perhaps refering to an actual source.Examples of tokens are : "the bꜣk-sign in Louvre C252", the A1 sign in Gardiner Font, the A1 sign in JSesh font, etc... In practice, for "the bꜣk-sign in Louvre C252", we would technically refer to a fac-simile rendering. Tokens will have unique codes. My opinion is that they should probably be mostly meaningless (that is, the code would be a simple numeral, perhaps with an author prefix, as suggested by JSesh fonts). The information needed to search and retrieve the token would be made of specific tags, much like the descriptive tags of JSesh signs.
Actually, a more precise representation of tokens would be that they point to an actual reference ("the bꜣk-sign in Louvre C252, line 2"), and that they have one or more computer rendering. In some cases (for instance, the token for sign A1 in the hieroglyphica, both the token and its computer rendering are isomorphic).
-
the most abstract type of code would be the sign. The sign is defined by its linguistic values, according to the usual substitution rules. For instance, there would be a sign for the the "owl", regardless of its actual representations, or one for the scribe outfit. The sign can have multiple values : in the last case, nꜥꜥ or sš (or sẖꜣ).
-
between the two, we might introduce a number of layers, called classes in the TSL. They group subsets of a sign occurrence, according to meaningful and discrete graphical feature, or selection in possible values (consider H6A vs H6, or specific variants of a determinatives).
In practice
Suppose we want to encode the following extract from the pyramid texts :
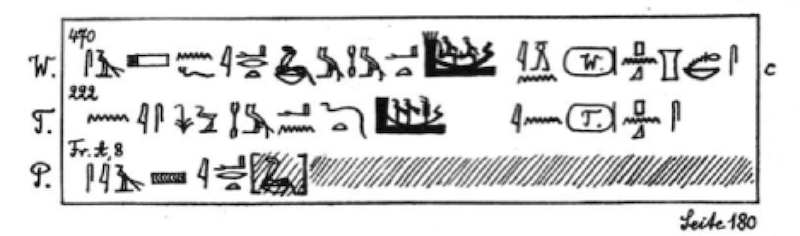
As handwriting is more versatile than a computer, Kurt Sethe, has visually distinguished the hieroglyphs. Most are drawn in his "normal" handwriting, as in s-A-siA-n:f 4 Other signs, most notably the boats, are drawn in black and filled. Sethe explains it in his preface:
(...) the peculiar forms of the signs have generally been reproduced with the greatest possible fidelity; only the consonant signs and a number of very common other phonetic signs (...) are given in the conventional normalised forms, which are immediately recognizable as such. And these signs, too, have usually been facsimiled where it mattered; for example, the goose in the name of God Geb, in the root ḥtm, in sꜣ "son," and in general as a phonetic sign for sꜣ, has been normalised, but where it was the determinative of a word for "goose (rꜣ, sꜣ-t, ꜣpd, smn) it has been given mostly in facsimile (...)
In our proposed system:
- using the sign code allows to keep a neutral position about the sign shape. It's probably the right thing to do in most cases when encoding hieratic ;
- using a class code allows to explicitly choose a specific sub-class of the sign. Note that "the most usual" or "most neutral" version of the glyph will be a class too, if we want to explicitly select it ;
- token codes, which refer to pictures, will be used when the class level is not precise enough, either for unclassified glyphs, or very peculiar variants in a class.
Display and interface
A very important point is that only tokens have a fixed graphical value. For display, an occurrence of a sign or a class would obviously be represented by a token. The most simple way to do this would be for each sign to have a default class, and each class to have a default token.
The way to select the particular token used to render a sign or a class might depend on multiple factors :
- suppose you have multiple fonts. A choice of font will change the tokens used for rendering signs and classes, but explicit tokens will allow the user to get facsimile-like signs when needed ;
- the default class for a sign might change diachronically. For instance, the default class used for the papyrus roll sign might point to Y1 for the Middle Kingdom onward, and to Y2 for the old kingdom.
Regarding the user interface: it is clear that this system is somehow more complex for the user. To make things easier, we would need to distinguish two cases:
- a typesetting mode, for users who simply want to print their hieroglyphs and would rather be left alone, thank you;
- a text-database mode, for users who want to have text encoding with clear semantics.
In the text-database mode, the user interface would use the same general system as JSesh uses currently, except that, by default, only signs will be available. A volontary decision will allow one to use classes, and an optional color code would be used to show which glyphs are encoded as signs and which glyphs are encoded as classes.
In the typesetting mode, the class level would be the default one.
Problems and limitations
There are a number of problems. For instance, should G43 and Z7 correspond to the same sign? In other cases, some hieroglyphs, with originally different values, as N37 and N37A may merge and become the same sign. Or, for many Old Kingdom determinatives, they could end put being subsumed by a generic sign such as A24.
There are also a few shapes which can be interpreted as many different signs. In particular, circles like US1Z13EXTU can be instances of ra, x, zp... Should we have a different token for circle as ra, circle as x, etc... and what should we do in this case for unidentified circles ?
The possibilities would be :
- that a given token might refer to multiple signs or classes. But in 99% of the cases, a token will either be unidentified or refer at least to a sign.
- use multiple identical tokens, which would, in the case of circles, force the user to choose explicitly which sign he sees behind the glyph. To be honest, I guess quite a few encoders, seeing r:US1Z13EXTU-Y1, will encode r:x-Y1. After all, a carved sign could have been originally painted, and appear as a plain circle just because the paint has vanished.
A graph based approach (describing relationships between signs) might allow to solve the problem, but with the cost of increased complexity in the user interface.
One can imagine also that two signs values may overlap, while the glyphs also retain values of their own. Should we then demote them to "class" status and create a sign which subsumes both?
My original layering was more complex than the one chosen for the Thot sign list. I thought that classes would have sub-classes, and so on. It's probably too complex.
-
see Meeks, Pal. Hierog. I, p. 143, 144 ↩
-
Polis, Stéphane and Rosmorduc, Serge, "Réviser le codage de l’égyptien ancien. Vers un répertoire partagé des signes hiéroglyphiques", in Document Numériques (2013), 16(3), 45-67 ↩
-
Meeks Dimitri, « Dictionnaire hiéroglyphique, inventaire des hiéroglyphes et Unicode », Document numérique, 2013/3 (Vol. 16), p. 31-44. DOI : 10.3166/DN.16.3.31-44. ↩
-
for the siA sign, compare for instance with Urk IV, 971, 1 ↩